SeeTraceAct: Visibility-Aware Latent Planning from Cross-Embodiment Demonstration Videos
Abstract
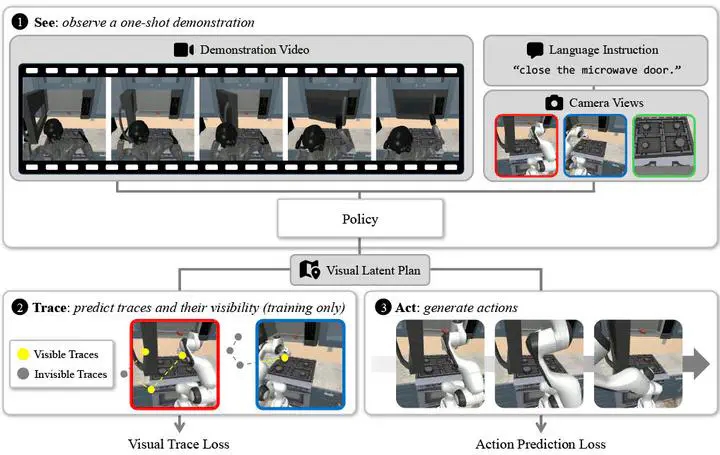
Vision-language-action models are promising general-purpose robot policies, but adapting them to new tasks typically requires costly task-specific teleoperation data. SeeTraceAct is a demo-conditioned VLA framework that improves spatial grounding through visibility-aware prediction of future end-effector traces, and is evaluated on RoboCasa-DC and a real-world benchmark.
Type
Publication
arXiv preprint arXiv:2606.02745
Junhyun Kim
M.S. Robotics Student
Robotics student interested in robot manipulation and vision-language-action models.